Logistic regression이 아닌 LDA(linear discriminant analysis), 선형 판별 분석은 언제 사용되는가?
- 두 개 이상의 response classes가 있을 때
- response classes가 잘 분리되어 있을 때 (logistic regression을 사용하면 불안정할 것이다)
LDA의 기본 원리
- 각각의 class에 분산되어 있는 X를 모델로 하고, Pr(Y|X)를 얻기 위해 베이즈 확률론으로 flip 한다.
- linear와 quadratic discriminant analysis는 X의 class에 대한 분산이 정규 분포(Gaussian)로 나타난다고 추정한다.
- linear 데이터는 linear discriminant analysis가, non-linear 데이터는 quadratic discriminant analysis(2차 판별 분석)가 더 나은 분석을 돕는다.
Resampling 접근은 왜 필요한가?
- 우리는 대개 큰 test set을 가지지 않고, function quality 판별을 위한 test error에 대한 추정치를 필요로 하기 때문이다.
Cross-validation
- 이용 가능한 샘플들의 세트를 두 부분, training set과 validation(hold out) set으로 랜덤하게 나눈다.
- 모델은 training set으로 fit(적용 또는 적합)되고, fit 된 모델은 validation set의 반응 관측치를 예측하기 위해 사용된다.
- validation-set의 에러는 테스트 에러 예상치를 제공한다.
- 테스트 에러는 주로 MSE, Misclassification rate의 방법으로 평가된다.
Cross-validation을 위한 방법으로는 무엇이 있는가?
- Validation set, K-fold CV, LOOCV
- K-fold cross valiation:
- K 수대로 데이터를 랜덤하게 나누고, K는 뺀 나머지 K-1들을 모델에 fit 시킨다.
- Kth 데이터를 위한 예측치를 얻는다.
- K = 1, 2, ..., K 각각의 파트를 반복한 뒤 결과를 합한다.
- LOOCV(leave-one-out cross-validation): K-fold와 비슷한 방식으로, (K=n) n-1 개수의 training observation을 통계 학습 모델에 fit 하고 예측은 이 observation을 배제한 채 MSE로 계산되어 만들어진다.
- MSE에 의해 선택되고 계산되는 과정을 반복한다.
- N-time 반복의 결과는 MSE1, ..., MSEn이 될 것이다.
Validation set 접근 방식의 단점은 무엇인가?
- 어떤 관측치가 training set과 validation set에 포함되었는지에 따라 test error의 변동성이 높을 수 있다.
- validation set에 속하기보다 training set에 포함되는 subset만이 모델에 fit 하도록 사용된다.
Bootstrap:
- 기원은 18세기 Rudolph Erich Raspe 작가의 "The surprising Adventures of Barn Muchausen"이란 책에 나온 구절 "pull oneself up by one's bootstraps"에서 파생되었다. 다른 분야에서도 조금씩 다르게 쓰이고 있는 단어로써, 일을 제대로 시작하기 전 준비한다(부츠를 동여맨다)는 의미로도 알려져 있다.
- 통계에서의 bootstrap은 resampling method에 속한다. 전집에서 independent data set을 반복해 얻는다기보다 원 데이터에서 샘플링을 반복해 얻은 관측치(observations)로 특정 data set을 가진다.
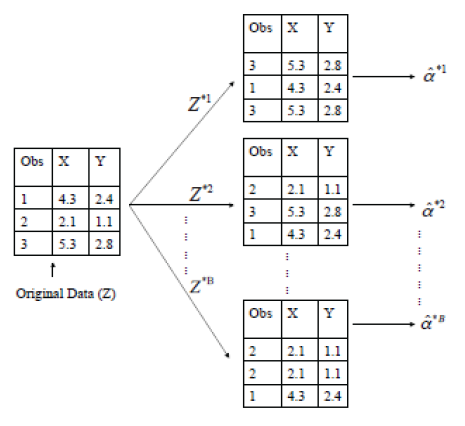
각 bootstrap data set은 n개의 관측치와 원 data set에서 replacement로 샘플링 된 data set을 가지고 있다. 각 bootstrap data set은 a(alpha)의 estimate을 얻는 데 사용한다.
- 계수의 표준오차 추정치를 얻을 수 있다.
- 신뢰 구간 = bootstrap 신뢰 구간
Regularization methods
- Subset selection
- Shrinkage
- Dimension reduction
'공부 > 통계' 카테고리의 다른 글
| [통계] Partial correlation 편(부분) 상관관계와 Multiple regression (9) | 2020.02.22 |
|---|---|
| [통계] Path Modeling 경로 모형 (4) | 2020.02.10 |
| [통계] Logistic regression 로지스틱 회귀분석 (4) | 2020.02.08 |
| [통계] Categorical regression 범주형 회귀분석 (4) | 2020.02.07 |
| [통계] 다변량 통계를 위한 기본적인 terminology (2) | 2020.02.07 |



